NVIDIA Inference晶片布局拆解:Groq LPU、HBSRAM与NVIDIA Inference战略
摘要
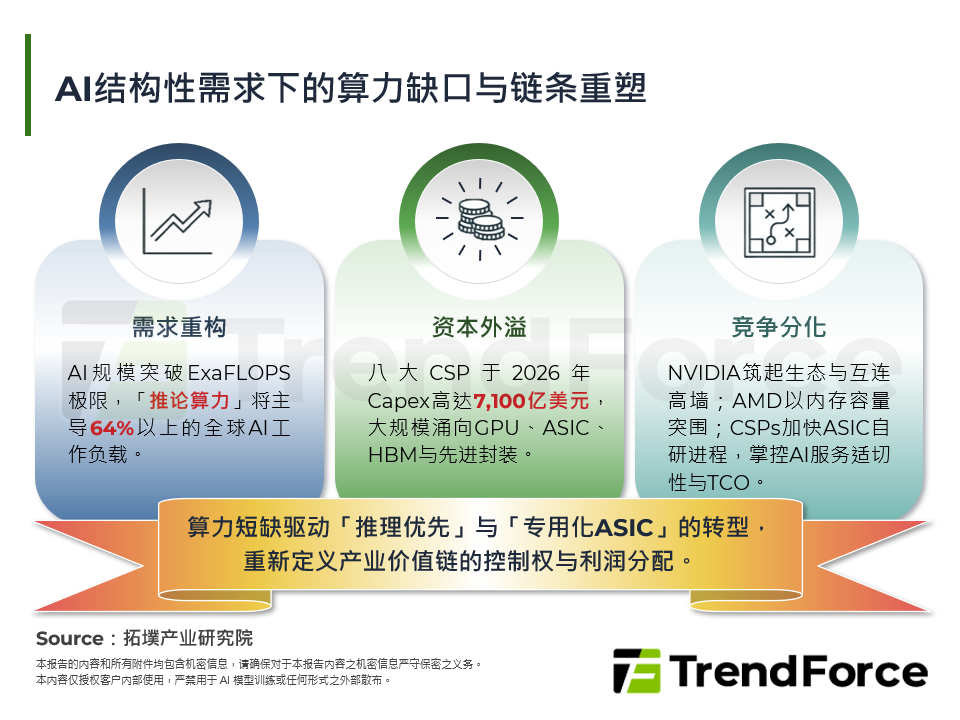
2025年12月24日NVIDIA以200亿美元实质掌控Groq的智慧财产权与团队,看中其以软体为主设计、以SRAM为核心记忆体的Groq LPU在极低延迟Inference的表现;此外,NVIDIA也于CES 2026强调记忆体容量成为AI Inference的新瓶颈。为突破记忆体瓶颈,预计 GPU-for-Everything的时代将迈向终结,而异质化记忆体阶层的新典范将展开。未来Hybrid Bonded SRAM、HBF皆成为AI晶片设计的潜在选项,以突破HBM在频宽、延迟、容量上的限制。因此本篇报告主要深度解析:(1) Inference晶片设计要求;(2) Groq LPU/GroqRack技术解析;(3) HBM vs. HBF vs. HBSRAM比较;(4) Groq LPU对NVIDIA的战略意义。期能为厂商与投资人解析Inference晶片要求、Groq LPU和HBSRAM的技术发展与未来可能性。
一. Inference晶片设计要求
二. Groq LPU/GroqRack技术解析
三. HBM vs. HBF vs. HBSRAM
四. Groq LPU对NVIDIA的战略意义
五. 拓墣观点
图一 Three Scaling Laws
图二 NVIDIA于CES 2026强调Context Window Size为新瓶颈
图三 2016~2024年Memory Wall
图四 NVIDIA Inference Context Memory Storage Platform Tray
图五 NVIDIA Inference Context Memory Storage Platform Rack
图六 Groq LPU晶片架构
图七 LPU序列处理与GPU比较
图八 GroqWare软体架构
图九 GroqRack配置示意图
图十 Groq产品系列图
图十一 GroqChip/GroqNode Scale-Out拓朴
图十二 记忆体阶层与HBSRAM、HBM、HBF
图十三 AMD 3D V-Cache堆叠示意图
图十四 AMD MI300堆叠示意图
图十五 SRAM单位元占用面积
图十六 各类型AI晶片Inference适用性比较
图十七 Cerebras WSE-3结构
图十八 Cerebras WSE-3多层式板载封装结构
表一 Inference Decode阶段性能的主要限制因素
表二 Prefill与Decode比较
表三 NVIDIA实测HBM、3D-DRAM、SRAM方案比较
表四 各类型处理器比较
表五 GPU、TPU、LPU比较
表六 NVIDIA新三层式记忆体架构
表七 Groq LPU、B200、TPU v7性价比分析
表八 各大AI晶片供应商Inference布局
表九 低延迟、高频宽、低功耗AI晶片主要供应商